
Several types of convolutional neural networks exist, including traditional CNNs, recurrent neural networks, fully convolutional networks and spatial transformer networks — among others.
Traditional CNNs
Traditional CNNs, also known as “vanilla” CNNs, consist of a series of convolutional and pooling layers, followed by one or more fully connected layers. As mentioned, each convolutional layer in this network runs a series of convolutions with a collection of teachable filters to extract features from the input image.
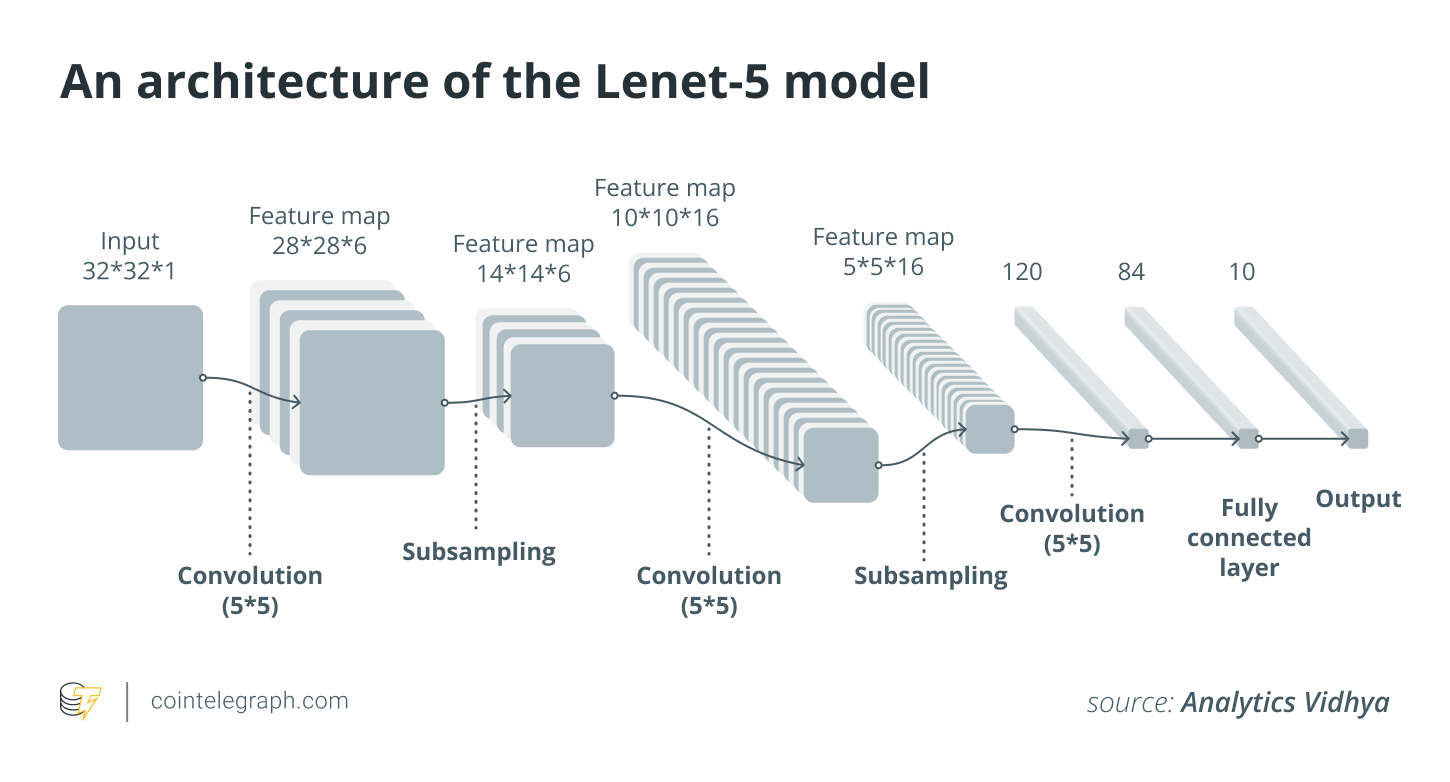
The Lenet-5 architecture, one of the first effective CNNs for handwritten digit recognition, illustrates a conventional CNN. It has two sets of convolutional and pooling layers following two fully connected layers. CNNs’ efficiency in image identification was proved by the Lenet-5 architecture, which also made them more widely used in computer vision tasks.

Recurrent neural networks
Recurrent neural networks (RNNs) are a type of neural network that can process sequential data by keeping track of the context of prior inputs. Recurrent neural networks can handle inputs of varying lengths and produce outputs dependent on the previous inputs, unlike typical feedforward neural networks, which only process input data in a fixed order.
For instance, RNNs can be utilized in NLP activities like text generation or language translation. A recurrent neural network can be trained on pairs of sentences in two different languages to learn to translate between the two.

The RNN processes sentences one at a time, producing an output sentence depending on the input sentence and the preceding output at each step. The RNN can produce correct translations even for complex texts since it keeps track of past inputs and outputs.
Fully convolutional networks
Fully convolutional networks (FCNs) are a type of neural network architecture commonly used in computer vision tasks such as image segmentation, object detection and image classification. FCNs can be trained end-to-end using backpropagation to categorize or segment images.
Backpropagation is a training algorithm that computes the gradients of the loss function with respect to the weights of a neural network. A machine learning model’s ability to predict the anticipated output for a given input is measured by a loss function.
FCNs are solely based on convolutional layers, as they do not have any fully connected layers, making them more adaptable and computationally efficient than conventional convolutional neural networks. A network that accepts an input image and outputs the location and classification of objects within the image is an example of an FCN.
Spatial transformer network
A spatial transformer network (STN) is used in computer vision tasks to improve the spatial invariance of the features learned by the network. The ability of a neural network to recognize patterns or objects in an image independent of their geographical location, orientation or scale is known as spatial invariance.
A network that applies a learned spatial transformation to an input image before processing it further is an example of an STN. The transformation could be used to align objects within the image, correct for perspective distortion or perform other spatial changes to enhance the network’s performance on a specific job.
A transformation refers to any operation that modifies an image in some way, such as rotating, scaling or cropping. Alignment refers to the process of ensuring that objects within an image are centered, oriented or positioned in a consistent and meaningful way.
When objects in an image appear skewed or deformed due to the angle or distance from which the image was taken, perspective distortion occurs. Applying several mathematical transformations to the image, such as affine transformations, can be used to correct for perspective distortion. Affine transformations preserve parallel lines and ratios of distances between points to correct for perspective distortion or other spatial changes in an image.
Spatial changes refer to any modifications to the spatial structure of an image, such as flipping, rotating or translating the image. These changes can augment the training data or address specific challenges in the task, such as lighting, contrast or background variations.